GENETICS
GENE DNA MOST MPORTANT FUNCTION PRODUCING PROTEIN
RNA THEN TRANSPORTS DNA INFO TO RIBOSOMES IN CELL TO MAKE A SPECIFIC PROTEIN
GENETICS


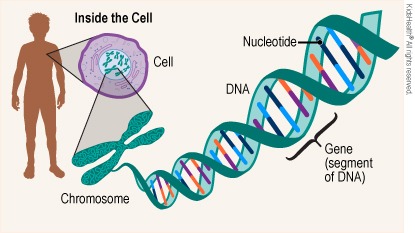
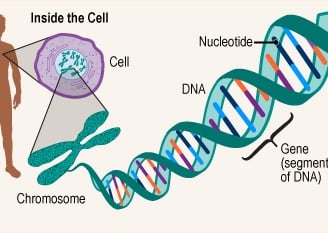
DNA is the genetic material responsible for inheritance and is passed from parent to offspring for all life on Earth. To preserve the integrity of this genetic information, DNA must be replicated with great accuracy, with minimal errors that introduce changes to the DNA sequence. A genome contains the full complement of DNA within a cell and is organized into smaller, discrete units called genes that are arranged on chromosomes and plasmids.
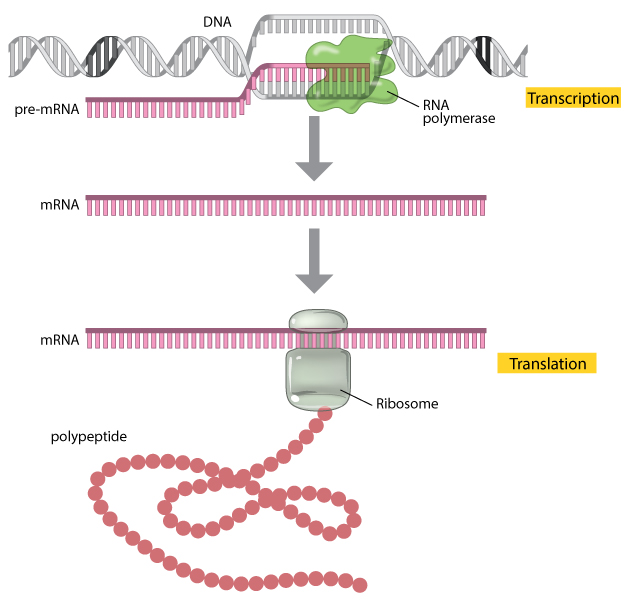
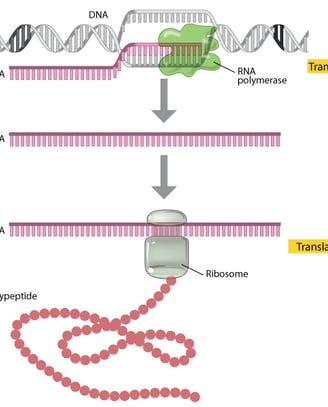
A gene is composed of DNA that is “read” or transcribed to produce an RNA molecule during the process of TRANSCRIPTION. One major type of RNA molecule, called messenger RNA (mRNA), provides the information for the ribosome to catalyze protein synthesis in a process called TRANS LATION The processes of transcription and translation are collectively referred to as gene expression.
Genes
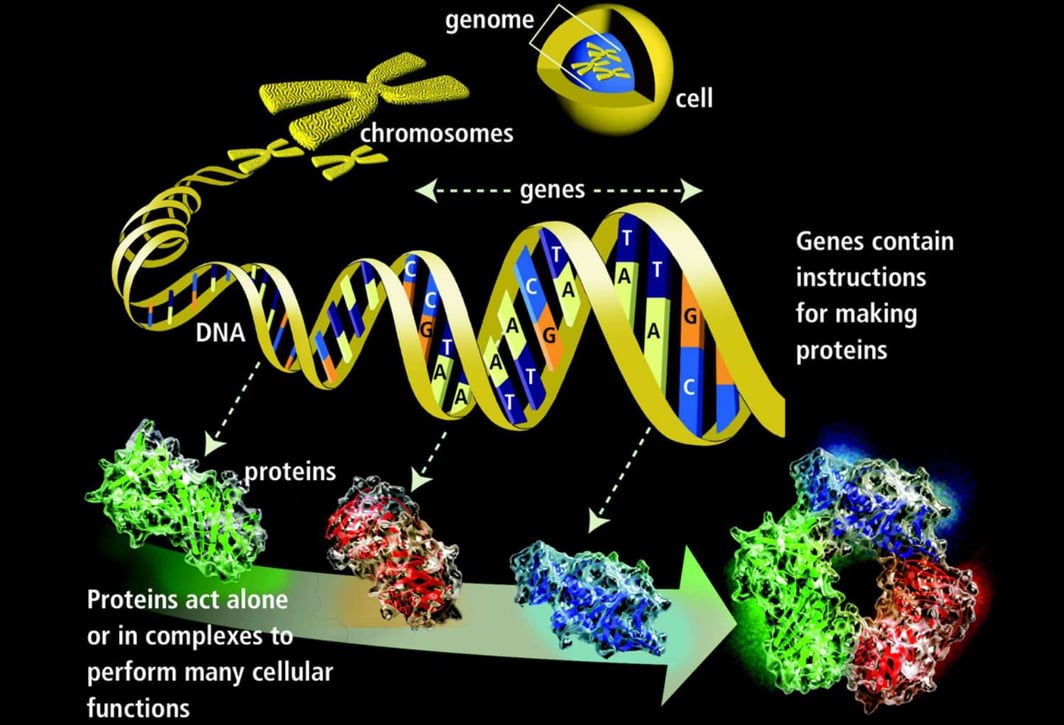
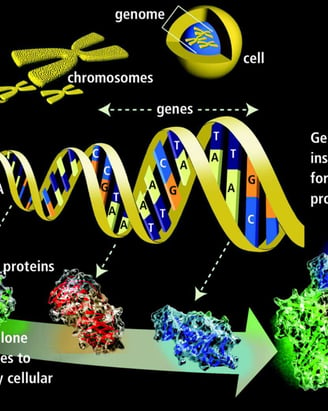
DNA (deoxyribonucleic acid) and RNA (ribonucleic acid) are both made up of chains of nucleotides, but they have slightly different chemical properties.
DNA contains the information and templates for making and maintaining all living things, while genes are specific portions of DNA that act as templates for making proteins.
During the process of transcription, a gene's DNA is used to create RNA, which then carries the information out of the nucleus and into the cytoplasm.
In the cytoplasm, the cell translates the information in the RNA to string together amino acids, which form a protein. These processes of transcription and translation are collectively called gene expression
The majority of genes carried in a cell's DNA specify the amino acid sequence of proteins;
The RNA molecules that are copied from these genes (which ultimately direct the synthesis of proteins) are called messenger RNA (mRNA) molecules
The final product of a minority of genes, however, is the RNA itself.


DNA to PROTEIN FORMATION
Protein
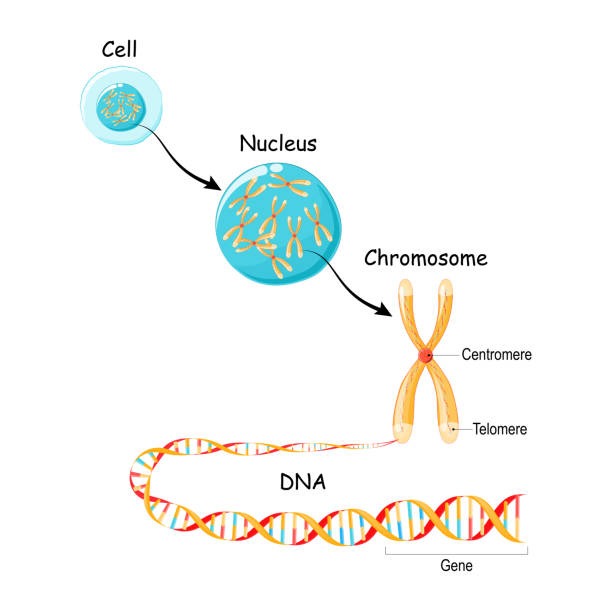
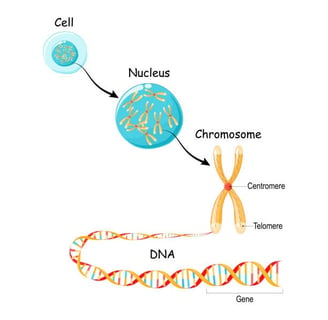
DNA strands are packaged into chromosomes with proteins, which allow cells to control gene expression (and phenotypes), replication of the DNA, and separation of the genetic material into cells as they divide. Most (but not all) Bacteria and Archaea have circular chromosomes, with the DNA strands forming a continuous loop. These loops are often twisted up on themselves so the chromosomes make compact structures in the cells .
The region in a cell with the condensed chromosome is called the nucleoid. Some DNA can also be housed in structures called plasmids that are more easily exchanged between organisms.
Eukaryotes organize their DNA differently. First, most of the DNA is encased in the cell nucleus, which is separated from the rest of the cell with a membrane. Within the nucleus, the DNA strands are packed into multiple linear chromosomes. DNA strands are wrapped around special proteins called histones (also present in some Archaea) and then folded into even tighter areas by additional proteins.
The folding of the chromosomes and the details of the chemical structure of long chains coming off the histones strongly influence whether or not genes on the chromosomes can be expressed. Eukaryotes also have DNA in other parts of their cells, specifically certain organelles, including mitochondria and plastids (which include chloroplasts).
The DNA in organelles (orDNA) is inherited from ancient bacteria that were the ancestors of these organelles. orDNA is packaged into their own chromosomes, whose structure varies among different organisms and even during development of a single organism. In general, orDNA structure is highly variable and poorly understood relative to nuclear DNA structure and replication
Chromosomes
BIGGER
SMALLER


Gene expression is the synthesis of a specific protein with a sequence of amino acids that is encoded in the gene. The flow of genetic information from DNA to RNA to protein is described by the central dogma .
Each of the processes of Replication, Transcription, and Translation includes the stages of
1) Initiation,
2) Elongation (polymerization)
3) Termination. These stages will be described in more detail in this chapter.
The central dogma states that DNA encodes messenger RNA, which, in turn, encodes protein.
A cell’s genotype is the full collection of genes it contains, whereas its phenotype is the set of observable characteristics that result from those genes. The phenotype is the product of the array of proteins being produced by the cell at a given time, which is influenced by the cell’s genotype as well as interactions with the cell’s environment. Genes code for proteins that have functions in the cell. Although a cell’s genotype remains constant, not all genes are used to direct the production of their proteins simultaneously. Cells carefully regulate expression of their genes, only using genes to make specific proteins when those proteins are needed Thus, their phenotype changes through time.
Phenotype is determined by the specific genes within a genotype that are expressed under specific conditions. Although multiple cells may have the same genotype, they may exhibit a wide range of phenotypes resulting from differences in patterns of gene expression in response to different environmental conditions.
What is the Cis and Trans phase in genetics?
When both the recessive or the dominant alleles for two traits are on the same chromosome, it is called the cis phase. However, when a recessive and dominant allele for the different traits are on the same chromosome, we call it the trans phase.Gene expression differences between species are driven by both cis and trans effects. Whereas cis effects are caused by genetic variants located on the same DNA molecule as the target gene, trans effects are due to genetic variants that affect diffusible elements.cis-regulatory differences appear to be more commonly responsible for adaptive evolution, though there are exceptions that illustrate the importance of gene network context in the path by which evolution proceeds.
Current evidence supports the supposition that genome-wide gene expression evolves under stabilizing selection. There is limited evidence that some of this stabilizing selection is due to compensatory cis–trans evolution,
MORE
Overall, when cis–trans contributions to gene expression differences are investigated there is an excess of compensatory cis–trans pairs.The observation of an excess of cis–trans pairs that are compensatory could be due to mutational and ascertainment bias, selection for compensatory mutations, buffering from gene-network feedback, or potentially communication between alleles (transvection).There is abundant variation in gene expression between individuals, populations, and species.
The evolution of gene regulation and expression within and between species is thought to frequently contribute to adaptation. Yet considerable evidence suggests that the primary evolutionary force acting on variation in gene expression is stabilizing selection. We review here the results of recent studies characterizing the evolution of gene expression occurring in cis (via linked polymorphisms) or in trans (through diffusible products of other genes) and their contribution to adaptation and response to the environment. We review the evidence for buffering of variation in gene expression at the level of both transcription and translation, and the possible mechanisms for this buffering.
Lastly, we summarize unresolved questions about the evolution of gene regulation .
Functional contributions of cis-regulatory sequence variations to human genetic disease are numerous. For instance, disrupting variations in a HNF4A transcription factor binding site upstream of the Factor IX gene contributes causally to hemophilia B Leyden. Although clinical genome sequence analysis currently focuses on the identification of protein-altering variation, the impact of cis-regulatory mutations can be similarly strong. New technologies are now enabling genome sequencing beyond exomes, revealing variation across the non-coding 98% of the genome responsible for developmental and physiological patterns of gene activity.
The capacity to identify causal regulatory mutations is improving, but predicting functional changes in regulatory DNA sequences remains a great challenge. Here we explore the existing methods and software for prediction of functional variation situated in the cis-regulatory sequences governing gene transcription and RNA processing.
At present the tools for the study of genome-wide regulatory sequence variations are limited, leading researchers to focus on variations predicted to alter genomic regions with well developed annotation - protein-coding sequences. This is due in part to the nature of the regulatory target and in part the availability of data. The cis-regulatory elements are short in length, widespread throughout the genome and are not confined to specific genomic landmarks - they can be both proximal and distal to their gene targets.
Computational predictions of regulatory elements, in turn, are faced with extracting short and variable signal from a large genomic space, in which there is a mixture of functional elements and apparent randomly occurring non-functional sequences
. Regulatory predictions are further complicated by the fact that the cellular environment and stage of development affects the functional activity of regulatory elements - an element that is active in one cellular context may not be active in another, an aspect important to the study of disease. However, from the current era of high-throughput technology, we can anticipate an increased understanding of the biological dynamics of cis-regulatory elements to feed into and improve computational algorithms predicting the locations of cis-regulatory elements. With improved predictions we will increase our ability to predict cis-regulatory-associated variants and their functional impact on the regulatory elements they coincide with.
The ability to look with increased resolution at the non-coding space of the genome has recently encouraged an increasing number of laboratories to investigate the impact of cis-regulatory-associated variants on disease, which as a result has motivated the development of bioinformatics tools for linking variants with regulatory elements. Bioinformaticians are still in the early stages of developing methods to integrate high-throughput regulatory data, such as ChIP-Seq and RNA-Seq, with regulatory element prediction, variant calling, and databases of known regulatory elements and variants. At the current time, researchers are best served by following a workflow such as that described here. However, a critical mass of interest in regulatory variants is being reached, and automated workflows will become publicly available in the near future.
The increased affordability of whole-genome sequencing has dramatically expanded the potential for studying cis-regulatory-related diseases in a familial context. The added power of having related genomes to study segregation of familial sequence variants with a phenotype dramatically improves the ability to predict disease-associated cis-regulatory variants. We anticipate that the next few years will see a rapid expansion of such family-associated studies.
Use of the aforementioned filters and tools in a workflow, as outlined here, coupled to the improved detection of causal variants provided by genome-wide data for multiple related individuals, provides medical genetic researchers with the means to prioritize the potential regulatory impact of a given a set of variants. In the future, integrated tools will consolidate the analysis process, bringing diverse analysis methods and data sources into a self-contained workbench for regulatory variation analysis.
GENE EXPRESSION
THIS DOES NOT INCLUDE THE NEWER FINDINGS SEEN IN THE EPIGENETICS CHAPTER
https://www.youtube.com/watch?v=MeKRueznCr8
https://www.youtube.com/watch?v=F1jBN00zda8
https://www.youtube.com/watch?v=hKU8JQOgYmU&t=50s
https://www.youtube.com/watch?v=B4YbNm06bD8
https://www.youtube.com/watch?v=IePMXxQ-KWY&t=7s
https://www.youtube.com/watch?v=FNynz6Q12Bw
https://www.youtube.com/watch?v=LtmAHmTLYy0
https://www.youtube.com/watch?v=G4VINRUe_o4
https://www.youtube.com/watch?v=4YKFw2KZA5o
https://www.youtube.com/watch?v=EPTeaXMVcyY
https://www.verdict.co.uk/drd4-7r-wanderlust-gene/?cf-view
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5477265/
https://www.nature.com/articles/hdy201054
https://genomebiology.biomedcentral.com/articles/10.1186/s13059-017-1250-y